Yes, but without intention.
It is more accurate to say large language models (LLMs) like ChatGPT “hallucinate” answers when confronted with questions outside their knowledge wheelhouse that they don’t have the ability to answer correctly. This is sort of like a politician lying to cover face, except LLMs have no face to cover and no concept of or moral conscience about lying.
Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations?
When large language models are aligned via supervised fine-tuning, they may encounter new factual information that was not acquired through pre-training. It is often conjectured that this can teach the model the behavior of hallucinating factually incorrect responses, as the model is trained to generate facts that are not grounded in its pre-existing knowledge.
Researchers at Cornell University studied the impact of such exposure to new knowledge on the capability of the fine-tuned model to utilize its pre-existing knowledge. To this end, they designed a controlled setup, focused on closed-book QA, where they varied the proportion of the fine-tuning examples that introduce new knowledge.
They demonstrated that large language models struggle to acquire new factual knowledge through fine-tuning, as fine-tuning examples that introduce new knowledge are learned significantly slower than those consistent with the model's knowledge.
However, they also found that as the examples with new knowledge are eventually learned, they linearly increase the model's tendency to hallucinate. Taken together, the results highlight the risk in introducing new factual knowledge through fine-tuning, and support the view that large language models mostly acquire factual knowledge through pre-training, whereas fine-tuning teaches them to use it more efficiently.
Stable Discussion
“In this paper, there's this really great graph that summarizes a lot of the difficult to understand details here but effectively it talks about what an LLM already knows about some set of data.

The LLM had some understanding of the training data, at least cause these are general purpose models, right? So they have some introductory understanding of what the data looks like here.
But then over time, as they trained in more data that model became clearer and clearer in its understanding of the unknown data set, right?
Until you approach a hundred.
As it goes over time, you can see that It initially had this kind of peak as it was being trained on new data it didn't know. But then at some point where this kind of dotted line is it begins to take a turn for the worst.
And the more it is trained on this unknown data set, the less accurate it is in general and the more prone it is to hallucinating answers. And so this is a really interesting study because it shows that while fine tuning is the way that we've thought about bringing data into an AI model.
This is basically saying, hey be careful. Because there's going to be a limit here to what you're able to do with that.
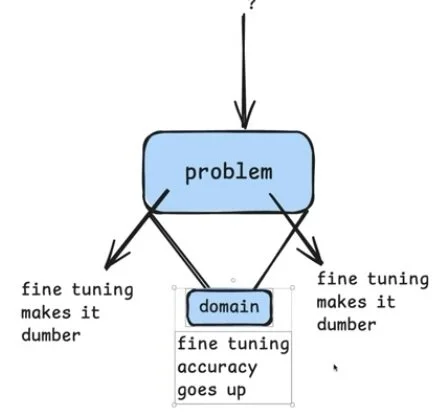
So you could imagine that I have some problem that I'm trying to solve, right? And if this problem is really specific, right?
Say this problem can really get boiled down to a very narrow idea or a very narrow point that needs to be solved. It's very deterministic. If it's domain is like very specific that it is only this small section that you will ever ask the LLM, right?
And you ask the system for something within this very specific domain.
Then, fine tuning, accuracy goes up, right?
And that's within this space.
But then, if your question falls outside of this domain area… where you fall outside of the space that you've trained on, right?
Because in a lot of the LLM solutions that we have today, we're asking questions that we don't necessarily know the user's going to ask. That's what makes the systems magic, right?
But if you ask something out here (outside the boundary), fine tuning makes it dumber, right? It knows less about the rest of the world.
It knows a lot about this space down here, but around all the rest of this space it really doesn't know as much